What is Reinforcement Learning?

Reinforcement learning (RL) is a powerful tool for building machine learning models that learn from interaction and are able to achieve specific goals. It differs from other types of machine learning, such as supervised learning and unsupervised learning, in that it does not require charted territory (labeled examples) and is not trying to find representations in the data (unsurpervised learning). Instead, the learning agent/bot takes actions and receives rewards or punishments as feedback, allowing it to learn which actions lead to the best outcomes and maximize the overall reward it receives. Formally, RL uses ideas from dynamical systems theory, specifically, "incompletely-known Markov decision processes".
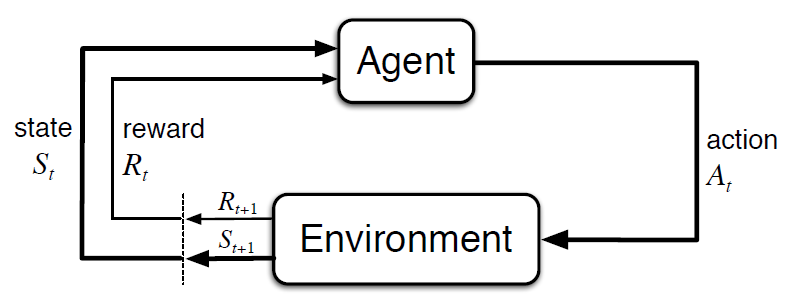
An RL system consists of an agent and its environment, where an agent is anything which percieves its environment and autonomously takes actions. In an RL system, there are four main elements: a policy, a reward signal, a value function, and a model of the environment (see below). The policy defines the agent's behavior and maps perceived states of the environment to actions to be taken (associations in psychology and the basis for human learning). The reward signal is the immediate goal of the RL system and is used to alter the policy. The value function specifies the total amount of reward that can be expected in the long-term, while the model of the environment allows the agent to make predictions about how the environment will behave based on a given state and action. It's important to note that when making and evaluating decisions, we use values since they provide the most reward to us over time.
One challenge of RL is the trade-off between exploration and exploitation. In order to maximize reward, the agent must exploit past behaviors that it has deemed rewarding. However, in order to find those behaviors in the first place, it must also explore and potentially lose reward. This exploration-exploitation dilemma remains an open area of research. However, significant progress has been made in value estimation, which is critical for solving RL problems, over the past 60 years. This progress has been driven by a shift in AI research towards the discovery of general principles rather than rule-based approaches.
RL has a wide range of applications, including building agents that can learn to optimize their performance in complex environments and tasks. For example, an RL agent could be used to build a learning player that can maximize its chances of winning against an imperfect opponent in a game such as tic-tac-toe. Classical optimization techniques, like dynamic programming, require a complete specification of the opponent's behavior, including the probabilities with which they make each move. RL methods can learn a model of the opponent's behavior from experience and apply dynamic programming, or use a value function to estimate the probabilities of winning from each state in the game. RL problems do not necessarily require an adversary, discrete time, or a finite state space, and can even work when certain states are hidden. However, a model of the environment can be useful in certain cases, such as in games with an infinite state space or when the agent is able to look ahead and know the states that will result from certain actions.

The history of RL can be traced back to two threads that eventually merged: the psychology of animal learning, optimal control and dynamic programming. The former thread centers around the "Law of Effect" proposed by Edward Thorndike, which states that behaviors that produce a satisfying effect are more likely to occur in similar situations, while behaviors that produce a painful effect are less likely to occur. The latter thread involves the Bellman equation and the class of methods used to solve it, known as dynamic programming. The concept of temporal difference learning, which has its origins in animal psychology, was brought together with optimal control in the development of Q-learning. Modern RL emerged in the 1980s with the convergence of these threads.
Sources¶
Sutton, R. S., Barto, A. G. (2018). Reinforcement learning: An introduction (2nd ed.). MIT Press Ltd.
White, M., White, A. (n.d.). Reinforcement Learning Specialization [MOOC]. Coursera.
